Why GPT-3.5 is (mostly) cheaper than Llama 2
posted by Aman
Llama-2-70B is an alluring alternative to gpt-3.5, but if looking for a cheap language model, it may not be worth it to deviate from OpenAI's API.
When considering price and latency:
Instead, Llama is best for prompt-dominated tasks, such as classification. Llama-2 may also make sense when:
- Your workload has no prompt tokens (unintuitive but we'll explain later)
- You are performing batch processing jobs
Otherwise, gpt-3.5 should be cheaper and faster.
A quick disclaimer, one reason to use Llama over gpt-3.5 is finetuning1. But in this post, we only explore cost and latency. I don't compare Llama-2 to GPT-4, as it is closer to a 3.5-level model. Benchmark performance also supports this claim:
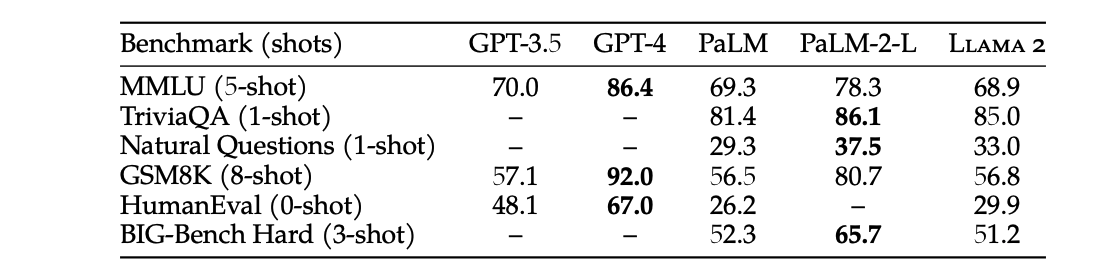
Figure 1: GPT-3.5 dominates llama in all benchmarks here 2
I'll prove these assertions by comparing the cost of serving Llama-2-70B with gpt-3.5-turbo given roughly similar latencies. We serve Llama on 2 80-GB A100 GPUs, as that is the minumum required to fit Llama in memory (with 16-bit precision)3.
On 2-A100s, we find that Llama has worse pricing than gpt-3.5 for completion tokens. We speculate competitive pricing on 8-A100s, but at the cost of unnacceptably high latency.
On the other hand, Llama is x cheaper than gpt-3.5 for prompt tokens.
A Primer in Transformer Math
With some straightforward math, we will show the following for Llama-2. For a sequence length of and a batch size of :
comes from twice the number of parameters of the model and 320 KB/s is derived with some arithmetic. In the following section, we explain how we arrive at these numbers.
There are other papers and/or blog posts that do a fantastic job of explaining transformer math. For inference, Kipply's post 4 is a great reference. And, I believe Scaling Laws 5 popularized the simplified equations used for transformer FLOPs.
To validate these numbers, we start with the architectural details for Llama. The hidden dimension is 4096, the number of attention heads is 64, the number of layers is 80, and the dimension of each attention head is 128:
Calculating Model Flops
The number of FLOPs for a forward pass is where is the number of parameters in the model. Every parameter in our model, belongs to some weight matrix And for each input token, each matrix is used exactly once in a matrix multiplication with a vector representing that token.
For each , we left multiply by a vector of dimension . The total FLOPs for this vector-matrix multiplication is 6, or 2 times the number of entries in the weight matrix. The total number of entries in all weight matrices of the transformer is the total number of parameters, , which gives total FLOPs barring attention.
The attention contribution to FLOPs is negligible for large models like Llama with (relatively) short sequences. For each layer and each attention head, The attention operation is:
requires multiplying a vector by a matrix, which is flops. The scaling factor and Softmax are negligible. Finally, multiplying the Attention vector by V requires an additional FLOPs. Summing across all attention heads and layers we get MFLOPs. So for our largest sequence of 8192, attention still only occupies GFLOPs of the full GFLOPs. It's small enough that we neglect it for simplicity.
Memory Requirements are Higher for Completions than Prompts
When generating tokens, we need to re-read all of the model's weights and the KV-cache to generate each token. What does that mean? To perform any matrix multiplication, we need to load the weights of each matrix from RAM into the GPU's registers. With enough unique matrices, the actual loading of the weights becomes the bottleneck rather than the matrix multiplication itself. So let's compare the path of a token through the model for prompts, and completions.
The memory path for generating tokens through a transformer
To illustrate this, we can follow the (very roughly sketched) path of a simple 1-layer transformer for generating a batch of tokens:
- We read the input embeddings matrix, and compute the corresponding embedding vector for each input in the batch.
- We read each of the matrices from memory to compute (vectors) for each input
- We perform the attention operation - which requires reading the cached keys and values. This returns a vector for each input
- We read from memory and multiply with the output of the previous step
- We read the output from step 1 and add it to the output of step 4, then perform layernorm
- We read and multiply to get the the output of the first feedforward layer
- We read and multiply to get the output of the second feedforward layer
- We read the output from step 5 and add it to the output of step 7, then perform layernorm
- We read the unembedding layer, then matrix-matrix multiply to get the token logprobs for each input in the batch
- We sample the next token and feed it back into step 1
Let's count up memory requirements. Across steps 1,2,4,6,7, and 9 we read all parameters of the model about once.7 On step 3, we read the KV cache of each batch element. On all steps, we read intermediate activations that are negligible compared to the model size. So the memory bandwidth requirements are Model Weights + KV Cache. As we increase the batch size, other than the KV cache, the memory requirements stay roughly constant! We'll come back to this later. Note that this is the memory requirement per token
The memory path for processing prompts tokens through a transformer
When processing prompts, we read all of the model's weights once, but incur the memory cost of Attention. Consider the rough path of a batch of sequences going through the same transformer:
- We read the input embeddings matrix, and compute the corresponding embedding matrix for each sequence in the batch.
- We read each of the matrices from memory to compute (which are matrices)
- We perform the attention operation
- We read from memory and multiply with the output of the previous step
- We read the output from step 1 and add it to the output of step 4, then perform layernorm
- We read and multiply to get the the output of the first feedforward layer
- We read and multiply to get the output of the second feedforward layer
- We read the output from step 5 and add it to the output of step 7, then perform layernorm
- We read the unembedding layer, then multiply to get the token logprobs for the prompt sequences
Across steps 1, 2, 4, 6, 7 we read all parameters of the model. On step 3, we perform the attention op which, using FlashAttention, requires far less memory bandwidth than reading the model weights (for reasonable length sequences and batch sizes). On all steps, we read activations, which are matrices that are negligible compared to the model size (also for reasonable length sequences and/or batches)8. Note that this is the memory requirement for all tokens.
The bottomline, the memory requirement per token for prompt processing is significantly less than generating tokens, because we batch the matrix multiplication across the sequence dimension for prompts!
Memory Bandwidth Needed for Model Weights
The model weights in 16-bit precision take up GB of memory
Memory Bandwidth Needed for KV Cache
The size of our KV cache is the size of all keys in values for all heads for all layers in the neural net, for all of the previous tokens, which is MB per token and batch element.
Llama 2 decided to remove multi-head attention. But instead of multi-query attention, they use grouped query attention, which improves performance. This results in 8 heads (or groups) for the keys and values, , rather than the normal 128 for multi-head, and 1 for multi-query.
For tokens, the size of our KV cache will be . Using 16-bit precision, that makes it KB. Given a batch size , we get KB.
For completions, this gives the memory requirement per token of:
The first term dominates for shorter sequences/small batches. Otherwise, the second term is much larger. However, since we only have 160GB of memory and the model takes up 140GB, the KV cache will impose a small cost on memory bandwidth in our experiments.
The memory bandwidth for prompts is around:
Communication Overhead
For simplicity, we ignore communication costs as accounting for model parallelism will significantly complicate things. We can reasonably assume that it won't add a large enough slowdown for any of our calculations (especially since we are only splitting Llama across 2 GPUs).
Prompt Processing is Really Cheap
Prompt processing or the time to first token is the most efficient part of transformer inference, and you should expect 3x price cuts relative to gpt-3.5.
For a model with -parameters and an -length prompt, the memory requirement for processing a prompt is about Bytes, while the compute requirement is FLOPs. Since A100s can handle 312 TFLOPs of matmul and 2 TB/s of memory bandwidth, we are compute-bound for sequence lengths .9
On A100s, FLOPs utilization will likely max out just a bit under 70% MFU. This amounts to around 200TFLOPs. 2-80GB A100s will cost us around $4.42/hr10, which comes out to $ /second. The FLOPs requirement for Llama is TFLOPs/token. Given the aggregate FLOPs for 2 A100s, we can calculate what the tokens per second should look like:
That's a price of:
$0.00042 / 1K tokens
Compared to gpt-3.5's $.0015 this is a steal! To be precise, it's an almost 4x price decrease!
Latency is also quite good! On our 2GPUs with a batch size of 1, We should be able to process 512 tokens in 170ms and 1536 tokens in 530ms.
Let's validate these claims with actual numbers. We use an internal fork of huggingface's text-generation-inference repo to measure cost and latency of Llama-2.
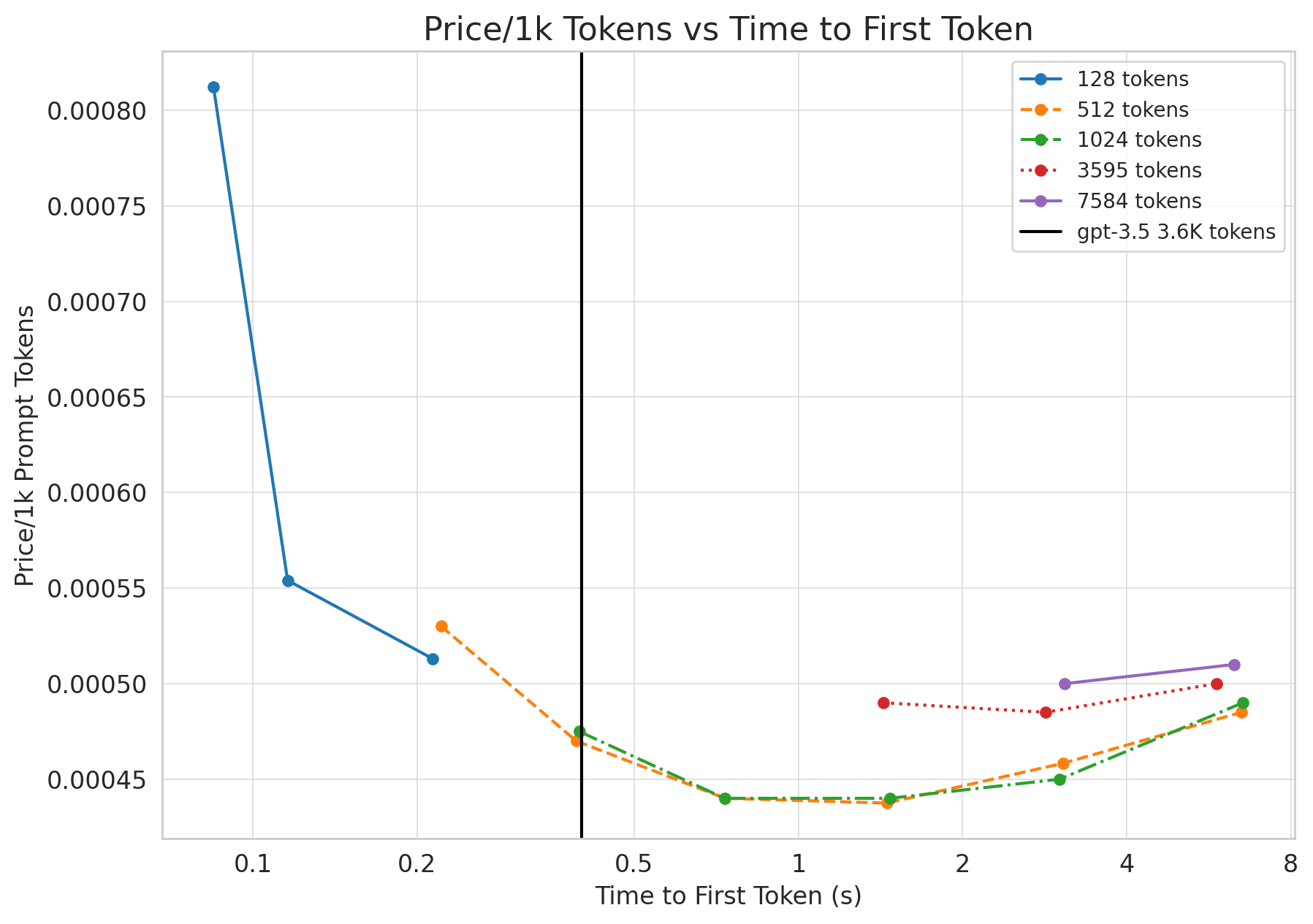
Figure 2: Each datapoint measures a different batch size. For prompt tokens, we always do far better on pricing than gpt-3.5, but trail slightly behind on gpt-3.5's latency of 0.4s for 3.6K tokens.
As we can see the price is significantly better than gpt-3.5's $0.0015/1k tokens! It does look like we lag a bit behind on time to first token for longer sequences, but the solve is quite straightforward. Parallelizing llama across 8 gpus (instead of 2) would give us an almost 4x speedup, meaning llama-2 dominates gpt-3.5 for prompts!
Generating tokens is slow and very expensive
In theory, it is possible to get competitive pricing to gpt-3.5 on completions, but in practice, you'll likely do worse.
When generating tokens, we move from compute-bound to memory-bound.11. Assuming, a batch size of 1, let's determine the throughput we can achieve.
Each 80GB A100 has peak memory bandwidth of 2TB/s per GPU. However, like FLOPs utilization, you can probably expect closer to 60-70% of that in inference workloads (1.3 TB/s). Since the KV cache is negligible at small batches, our throughput on 2-A100s will be:
Our new prices are much worse. At $0.0012/sec, we're getting a cost of...
This is abysmal pricing and speed for a gpt-3.5 level model! But remember the note from earlier on batch sizing. We're so memory bottlenecked that we can increase the batch size with no drop in generation speed. The higher our batch size, the lower our costs.
We can't increase to infinity, as our KV cache will eventually take up all of GPU RAM. Luckily, grouped-query attention helps alleviate this issue. For tokens, a batch size of , and 16-bit precision, our cache will be Bytes. In the case of 4096 tokens, this equates to 1.3GB of memory for a batch size of 1. We have 160GB of space on our 2-A100 machine. Our model takes up 135GB of this, leaving just 25 GB of space for the KV cache. Due to additional inefficiencies in memory storage. our max batch size for longer sequence lengths is around 8.
Given the (roughly) 8x speedup, we can expect a price of $0.00825 / 1K tokens. This is still worse than gpt-3.5-turbo, but closer. For shorter sequence lengths (1k total tokens), we should be able to increase the batch size to 32, meaning a price of $0.00206 / 1K tokens. In theory, this is competitive with gpt-3.5-turbo.
Another solution is increasing the number of GPUs. By renting 8-80GB A100s, we get 1.28TB of memory. Removing the model weights, we have over 1TB of memory left over for the KV cache, meaning a batch size of > 512 tokens is possible. Note that we wont actually see a 512x cost decrease, as the KV cache now takes up 8x more memory bandwidth than the model size, meaning it would be closer to a 64x cost decrease.
Using more compute also solves the latency issue. GPT-3.5 hits around 70 TPS. Splitting the model across 8GPUs instead of 2 should bring us around tokens/s.
We didn't have access to 8 A100s when running this experiment, but let's take a look at the numbers on 2-80GB A100s:
Measured Generation Performance
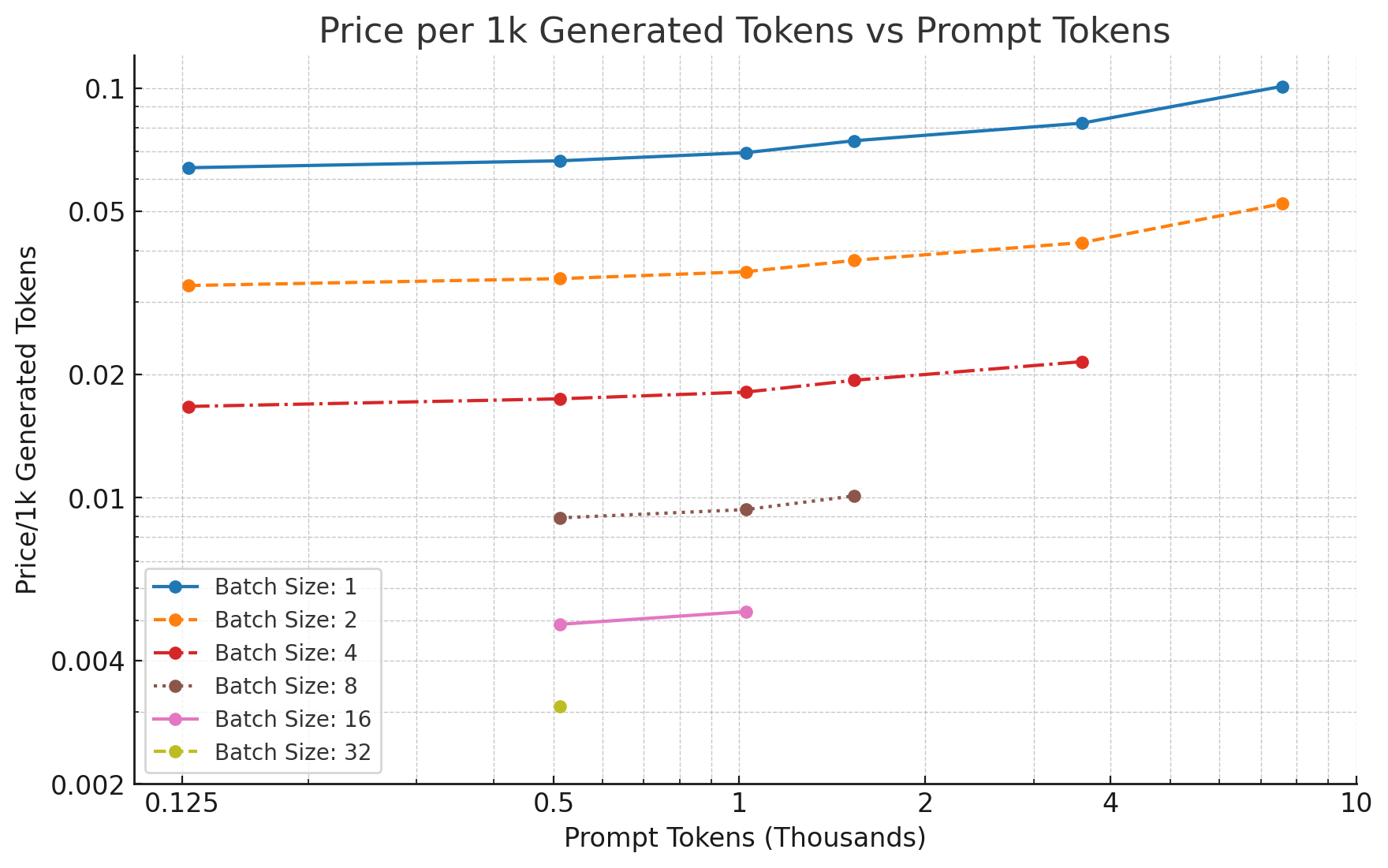
Figure 3: For all datapoints, we measure price per generated tokens when generating 512 tokens
These numbers are pretty close to what one would expect given the memory bandwidth calculations.
As we can see, increasing the batch size directly results in almost linearly decreasing costs for price/1K tokens. However, we still trail a decent bit short of GPT-3.5 pricing of $0.002/1K tokens - especially for longer sequence lengths.
Large Batch Sizes Mean Unacceptable Latency
Running generation with large batch sizes means gpt-3.5 competitive pricing, but it spikes the time to first token. As we increase our batch size, costs go down linearly, but time-to-first token also increases linearly.
A batch size of 64 brings us to better pricing than gpt-4. But, a batch size of 64 gives us:
a time to first token of almost 3 seconds for only 512 tokens!12 A batch size of 64 for 3596 tokens is 20.1 seconds.13 As a result, the kinds of workloads where Llama-2 would make sense relative to OpenAI's API are:
-
A large prompt with little to no generated tokens — handling pure prompts is remarkably simple.
-
Generating tokens with a small or no prompt — we can tune the batch size up to and get competitive pricing with gpt-3.5-turbo without sacrificing latency.
-
Offline batch-processing jobs that are not latency-critical.
Turning up the batch size requires consistently large workloads, which most startups will not have! For most users and most workloads, usage is incredibly bursty. Of course, a candidate solution is auto-scaling up and down on-demand GPUs, but even so, you can probably expect on average 50% of max throughput per-GPU - especially given cold boot times.
Our recommendation is to use open-source models for prompt-heavy tasks and leave generation-heavy tasks to closed-source models like gpt-3.5
Quantization
Most quantization methods are lossy, meaning some performance degredation. We can likely achieve mostly competitive performance with 8-bit quantization, giving a 2x price decrease on all calculated numbers! Quantization and imperfect utilization cancel each other out, meaning accounting for both, we expect similar prices to what we've measured!
However, the goal of most open-source quantization methods is to allow easy deployment on few/small consumer GPUs rather than optimized throughput at scale.
There are several open-source libraries that optimize for even lower precision quantization while maintaining performance. However, these libraries optimize for serving these models on few/small non-datacenter GPUs rather than throghput at scale. Specifically, they optimize for the low-batch inference case (mainly a batch size of 1). Despite offering (at best) 3-4x speedups, that still corresponds to a price of $0.017/1K tokens.
Bits and Bytes
Bits and Bytes offers (effectively) lossless quantization, meaning no difference in performance. However, it's main benefit is reduced memory usage rather than speed. For example the speedup of the recent NF4 representation is only on matmul speed, rather than inference throughput. Empirically, people don't seem to be measuring speedups on that front. 14
It is also unclear how well it scales to larger batches.
llama.cpp
I believe Llama.cpp is mainly optimized for Apple hardware. They also have Cuda support, and support fast 4-bit precision for inference, but my suspicion is naive quantization here would result in significantly degraded performance.
Also, this library is optimized for the low-batch regime.
GPT-Q
GPT-Q is another quantization library. I have not tested GPT-Q, but plan on doing so. Hopefully we can see a 2x price reduction here!
Once more, the implementation is optimized for the low-batch regime. In addition, the >3x speedup reported in the paper is only for 3-bit quantization, which is too lossy our use-cases.
How Exactly are Closed Source Models Cheaper?
There are several methods closed-source models use to be dramatically speed up inference
Quantization
As mentioned earlier, there are several solid open-source quantization methods - but I suspect OpenAI's quantization implementations are better optimized for larger batches.
Mixture of Experts
it is widely speculated GPT-4 uses mixture of experts 15. If gpt-3.5-turbo also uses MOE, then for the same level of performance you can serve a MUCH smaller (and therefore faster) model
Speculative Sampling
Speculative sampling is another interesting trick that gets around the slow decoding time of language models by having a smaller model draft several tokens in a row. 16. Note that in the limit this will not offer significant increases in throughput, but can drastically reduce latency. For reference, this repo implements a simplified version of it.
Fancy tricks for Inference at Scale
When running inference at scale, OpenAI can probably do fancy things like allocate several 8-GPU nodes for prefilling a batch of requests, then allocate a single 8-GPU node for generating tokens on that batch of requests. This would give them the best of both worlds, where they can use batch sizes > 64, and still see a ridiculously low time to first token.
Closing thoughts
We've used these findings to inform how/when we decide to use Open-source models at Anysphere.
To recap, we find it most helpful to use open-source models for prompt-heavy tasks, such as classification or reranking
Come work with us at Anysphere!
We're building Cursor, an AI-first code editor. When fundamentally re-imagining the development environment, we get to tackle loads of very interesting problems. For example, finetuning and serving models for a fraction of the price of OpenAI's API.17 Or designing new abstractions for creating complex chains and agents with OpenAI's API.
We're a small team of 5 based out of SF and backed by OpenAI. If interested, please reach out at hiring@anysphere.co.
Or, if you want to talk shop about language models, dm me on twitter.
Appendix
Below is the table of datapoints with measurements on Llama-2-70B latency as well as some additional calculated metrics
Footnotes
-
For full disclosure, we are funded by OpenAI, but we are as impartial as possible in this analysis. For example, we believe open-source models are better suited for prompt-heavy tasks than gpt-3.5! ↩
-
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/ ↩
-
And I couldn't provision any 4/8-GPU nodes despite having capacity ↩
-
Chen, Carol. "Transformer Inference Arithmetic", https://kipp.ly/blog/transformer-inference-arithmetic/, 2022. ↩
-
For matrix multiplication of an matrix with an matrix, it's a straightforward proof to show the number of flops. A dot product between two -dimensional vectors is FLOPs, as we perform separate multiplications, then additions to sum the array of multiplied coordinates. Matrix multiplication performs dot-produces, where each vector is -dimensional. This means the total FLOPs for a matmul is . For vector matrix multiplication, , so the FLOPs are just . ↩
-
We read the emmedding matrix twice, but it is small enough compared to the model size that we can ignore it. ↩
-
For large enough sequence lengths, the actual intermediate activations stored end up using memory bandwidth more than model weights and a comparable amount to flash-attention. This paper uses a flash-attention like technique to reduce memory bandwidth for these intermediate activations: https://arxiv.org/pdf/2305.19370.pdf ↩
-
In fact, this is likely why it feels like the time to first token is almost constant for small prompts. Both the compute/token and memory bandwidth/token are or 2 times the number of parameters. Since FLOPs are 312 for an A100 in 16-bit precision. Since memory bandwidth depends only on the number of generated tokens and FLOPs depends on prompt and generated tokens, the time to first token is memory bandwidth bound (and therefore constant) until the number of prompt tokens is tokens. ↩
-
Convince yourself that this is true by considering the memory and compute requirements for Llama ↩
-
On , we can expect TFLOPs of compute. However, for 512 prompt tokens with a batch size of 64, that is 32,768 tokens. This means latency will be ↩
-
With the same 1600# TFLOPs of compute, we need to handle 3596 prompt tokens. First off, with this sequence length and batch size, we may be memory bound once more with flash-attention, slowing things down further. Even ignoring that, this would be 7x slower than before, meaning 20.09s ↩
-
See this huggingface post and this tweet ↩
-
https://www.semianalysis.com/p/gpt-4-architecture-infrastructure ↩
-
This is something we do a vanishingly small fraction of the time. For most tasks, we've found OpenAI's gpt-3.5 and especially gpt-4 dominate open-source models. ↩